I’ve been following with interest the debates around the rapid emergence of powerful large language models such as OpenAI’s ChatGPT, its Bing sibling Sydney, Meta’s Galactica, and Google’s Bard. One important recent discussion of this can be found here. My current status: deep concern mixed with pragmatic curiosity.

Given the propensity of ChatGPT (mid-February, 2023 version) to happily invent facts, people, nonexistant citations, and quotations, I’m not yet too worried about how this impacts historical essays produced by students. However, while its shortcomings in this regard may give only temporary relief as these models evolve, it also limits its usefulness for quick information lookups on things you are not already expert enough on to call bullshit on. So are there any current use cases for historians? I stumbled on one potential use through a post on Mastodon: apparently, ChatGPT is not bad at cleaning up and formatting tables from raw text.
To test this, I took some very badly formatted data from a single table randomly chosen from my photo of a March, 1946 issue of a Summation of United States Army Military Government Activities in Korea. Here is a view of the original table:
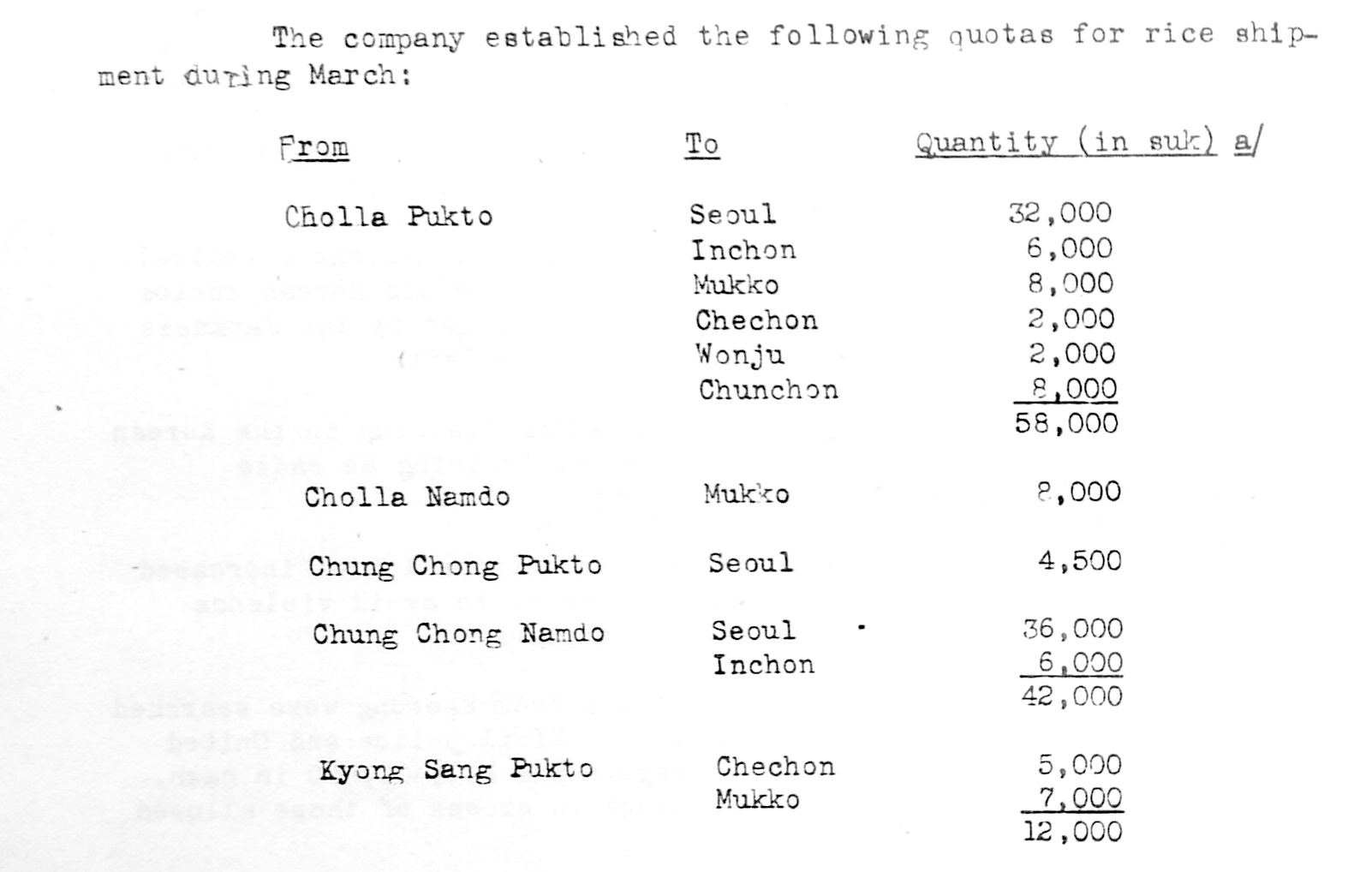
Here is the poorly formatted text extracted from this:
From To Quantity (in suk)
Cholla Pukto Seoul 32,000
Inchon 6,000
Mukko 8,000
Chechon 2,000
Wonju 2,000
Chunchon 8,000
__________
58,000
Cholla Namdo Mukko 8,000
Chung Chong Pukto Seoul 4,500
Chung Chong Namdo Seoul 36,000
Inchon 6,000
______
42,000
Kyong Sang Pukto Chechon 5,000
Mukko 7,0000
_______________
12,000
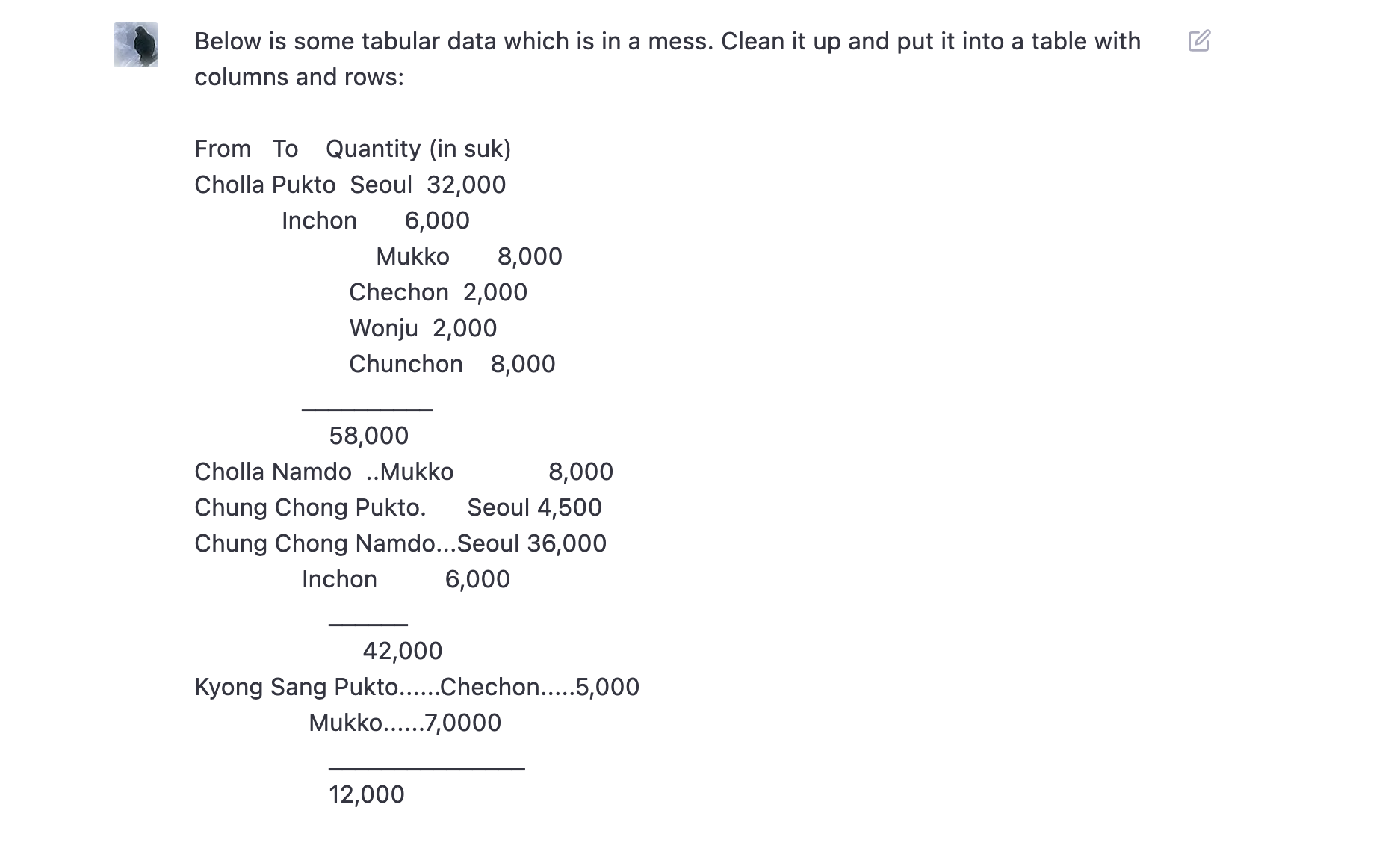
Now give ChatGPT the instructions to clean up the table:
This produced the following:
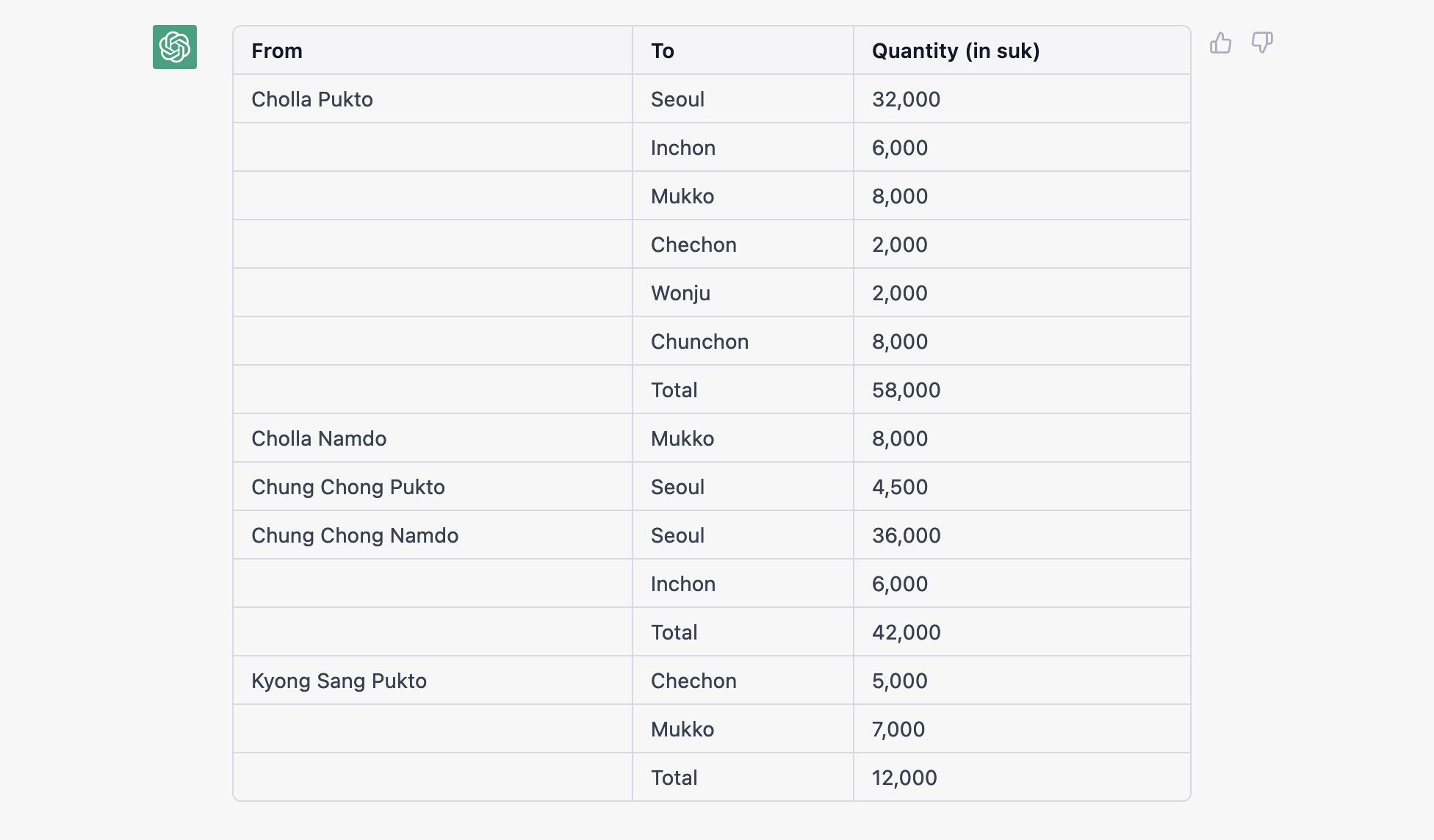
Selecting the text from the entire table, copying (from Firefox browser, in my case) and pasting it directly into (Mac) TextEdit or Microsoft Word retained the table formatting perfectly. But here it is again below. I asked ChatGPT to reproduce the table as HTML for easy copy/paste here with prompt: “reproduce this table as html”:
| From | To | Quantity (in suk) |
|---|---|---|
| Cholla Pukto | Seoul | 32,000 |
| Inchon | 6,000 | |
| Mukko | 8,000 | |
| Chechon | 2,000 | |
| Wonju | 2,000 | |
| Chunchon | 8,000 | |
| Total | 58,000 | |
| Cholla Namdo | Mukko | 8,000 |
| Chung Chong Pukto | Seoul | 4,500 |
| Chung Chong Namdo | Seoul | 36,000 |
| Inchon | 6,000 | |
| Total | 42,000 | |
| Kyong Sang Pukto | Chechon | 5,000 |
| Mukko | 7,0000 | |
| Total | 12,000 | |
You might notice that the model added “total” where it detected sub-totals for some sections. Also notice that the mistakenly transcribed 7,0000 is converted to 7,000 in the reply, but back to 7,0000 in the HTML table when I requested it in the next prompt (h/t to Janis for noticing this). Clearly a reminder to check the results as carefully as with OCR outputs.
There are lots of other places online that offer services for cleaning up messy data, but I have had mixed results with them. This worked quite well and can potentially save a lot of time cleaning up tabular data in OCRs of historical documents.